ADR 0008: 基於 fencing token 的 Capture 協調(epoch 圍欄層級投影)
狀態
已提議。核准為實驗性實作 — 2026-05-31。
此 ADR 以 ADR 0006: CloudEdge Event Federation、 ADR 0007: Provider Action Execution 和 Selective Address Mobility 資料平面為基礎。 屬實驗性質。
替換「持久化 de-provision 標記」修復(commit 26f2a729、issue #70)中引入的 de-provision 機制。該修復將 unassign 設為持久化的,但保留了 命令式 cancel 路徑(當位址重新變為 desired 時,取消進行中的 de-provision)。 該 cancel 路徑是非確定性的 — reconcile 時序與執行競爭 — 對狀態匯合點打補丁 無法消除 flaky。此 ADR 用 epoch 圍欄層級投影替換之。
背景
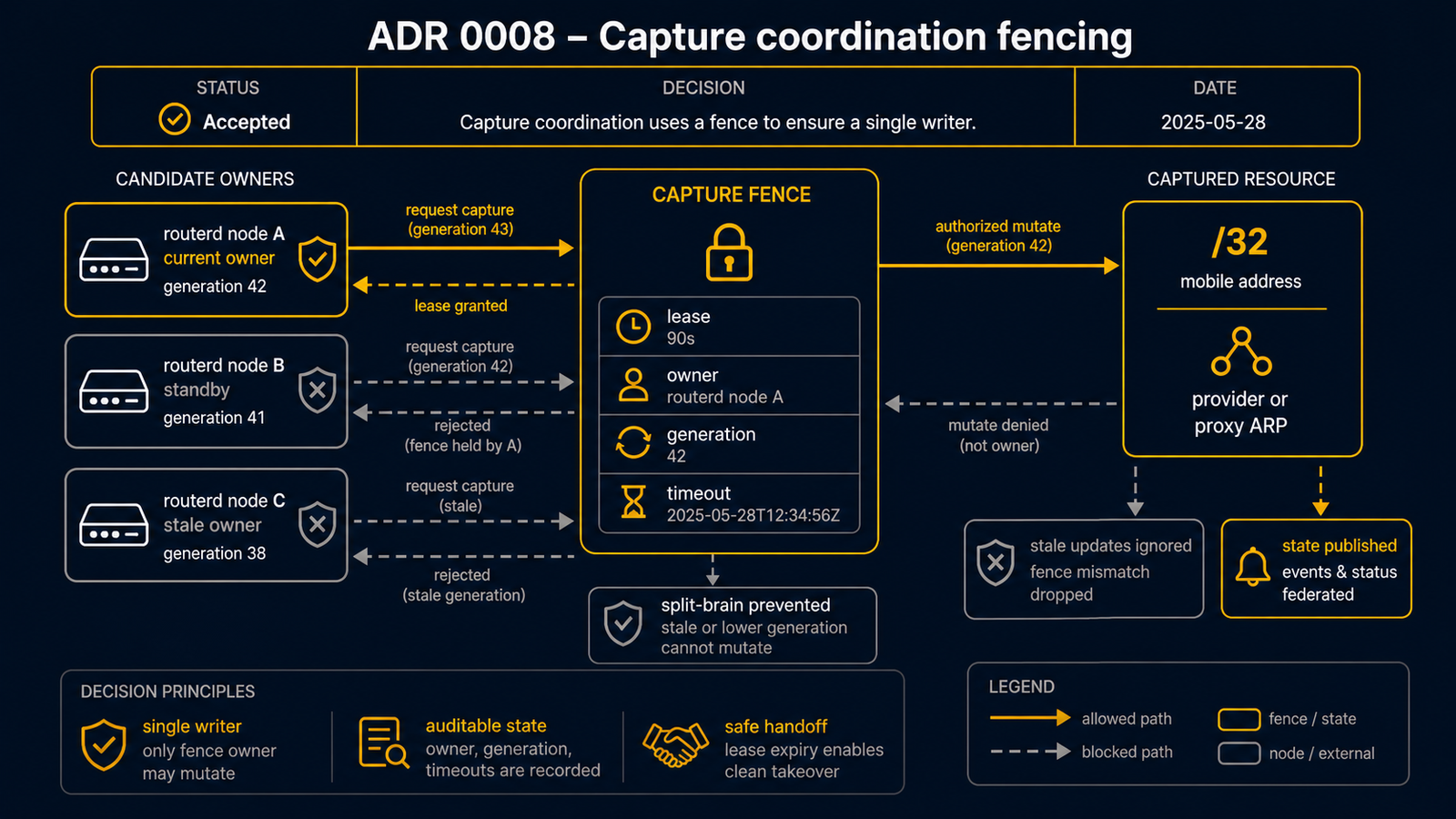
Selective Address Mobility 的行動 /32 是具有唯一性約束的共享資源,
在任意時刻恰好有一個 capture 持有者(any-origin 對稱仲裁的單一擁有者不變量)。
「持有」位址意味著擁有物理 capture:雲端 NIC 上的 provider secondary IP
配置(AWS ENI / Azure NIC / OCI VNIC),或 on-prem 的 proxy-ARP + GARP。
capture 以兩種方式在持有者之間轉移:
- 協調式 / 計畫式 — 維護排空。活躍持有者配合。
- 突發式 / 故障 — 持有者的主機停止或分割。無法配合, 備援方需要 seize(奪取)capture。
de-provision(secondary IP 的 unassign / 轉送的停用)是 capture 的釋放,
assign 是取得。此 bug 表現為 flaky 測試
(TestServeChainMobilityCancelsPendingDeprovisionWhenDesiredAgain,
無 -race 約 3/30 失敗):
re-capture 時進行中的 de-provision 有時未被取消,
遺留了孤立的標記 / pending action。對 cancel 匯合點打補丁無法消除 flaky。
對進行中工作的命令式取消是 level-trigger reconciler 的錯誤抽象。
參考的理論(分散式協調)
- Fencing token(Kleppmann, How to do distributed locking):帶 TTL 的 lease/lock 是活性所必需的(停止的持有者 lease 過期,備援方可接管), 但安全性不充分 — 暫停/延遲/復活的(「殭屍」)舊持有者在 lease 過期後仍可能 執行操作。「在寫入前檢查過期時間無法修復。」唯一的修復是 受保護資源檢查的單調遞增 fencing token, 拒絕 token 低於已見最大值的操作。
- Generation / term / epoch:Raft 的 term、ZooKeeper 的 epoch / zxid 等是同樣的 單調遞增 fencing token,用於殭屍圍欄和偏離狀態的 reconcile。 「下游系統必須拒絕帶有 stale epoch 的操作。」
- Level-trigger reconciliation(Kubernetes 控制器):每 tick 從觀測狀態 reconcile 到 desired 狀態。冪等。不在邊沿上運作。 嫁接到 level 迴圈上的邊沿邏輯(「re-desire 時取消 X」)會產生競爭。
- 腦裂 / HA 故障切換(Pacemaker STONITH、keepalived VRRP + EC2
AssignPrivateIpAddresses):浮動 IP 恰好由 1 個 master 持有 (IPaddr2 + GARP)。STONITH 在接管前保證舊節點停止。 心跳間隔權衡偵測延遲和腦裂風險 — 但不提供安全性。 安全性來自 fencing/仲裁。
routerd 特定的約束
此處的「受保護資源」是雲 provider API 和 on-prem 的 ARP 表, 兩者都不原生檢查 fencing token — AWS 不會因為 epoch 34 已發生而拒絕 「帶 epoch 33 的 unassign」。無法將 fencing 推到實際資源層面。 routerd 需要在自身控制的最後一道閘門強制執行 fence: action 匯入 / executor 邊界(「fencing proxy」模式)。
決策
1. captureEpoch — 每 (pool, address, captureDomain) 的單調遞增 fencing token
持久化的嚴格單調遞增本機計數器。
以 (pool, address, captureDomain) 為鍵,每當 desired capture 持有者變更時遞增
— 包括向之前的持有者 re-capture。與 AddressLease 的 epoch 不同:
AddressLeaseepoch = 位置擁有者(擁有位址者)的 epoch。captureEpoch= 物理 capture 持有者(attach secondary IP / 回應 proxy-ARP 者)的 epoch。
這是不同的生命週期,不得混淆。wall-clock time(now)
不得用作 token — 跨節點非單調,會導致 churn。
這是被替換修復的潛在缺陷。captureDomain 是 placement group 的
範圍(provider:<ref>:placement:<group>),同一 provider group 內
爭奪同一位址的所有 routerd 共享一條 epoch 線。
2. 所有 provider action 打上 (captureEpoch, captureKey, holder) 戳
planner 為 assign-secondary-ip、unassign-secondary-ip、轉送 action 打上
captureEpoch、captureKey、action 的目標持有者(acquire → desired 持有者,
release → 退出節點)戳。idempotencyKey 以 :epoch:<N> 為後綴,因此
capture epoch N 的 action 與 epoch N+1 的 action 具有不同的穩定 key — 且
在同一 epoch 內的 reconcile 間保持穩定(無 churn)。
3. de-provision 意圖是層級投影,不是工作佇列
de-provision 工作集 = 以目前 captureEpoch 評估的
(之前 capture 過的 − 目前 desired) 的投影,每次 reconcile 重新計算。
re-capture 不「取消」任何東西:位址重新進入 desired 狀態因此從投影中移除,
captureEpoch 遞增。不存在命令式 cancel 路徑。
持久化標記資料表作為 outbox 保留(僅靠 DynamicConfigPart
在匯入前會遺失意圖 — 原始 #70 故障)。但標記是
epoch 鍵控的投影項目,而非可取消的邊沿狀態。
stale 標記由同一 fence(dropStaleDeprovisionMarkers)清除。
4. 在匯入 / executor 閘門處圍欄
匯入位址 X 的 provider action 前、以及掃描日誌時,
將其 captureEpoch/holder 與 X 的目前 captureEpoch 比較:
- epoch 與目前不匹配,或 holder 不再是目前者的 acquire,
或 holder 仍是目前者的 release → action 為 stale → 跳過(圍欄),
已匯入的 pending/approved stale action 標記為
skipped。 試圖復活被替換標記的舊 reconcile 因持有舊 epoch 而在此閘門處被終止。
此單一確定性閘門替換了分散的
cancelMarkerPlansForDesired / CancelActionByIdempotencyKey 取消邏輯。
5. 為何安全 — 以及誠實的限制
- 節點內: 本機
captureEpoch閘門在節點的 reconcile 迴圈內是單調且序列的。 確定性地圍欄 stale 的本機 reconcile。這是消除 #70 flaky 的機制。 - 節點間(對先前過度聲明的糾正 — 每節點 DB 閘門在跨節點時
不是 linearizable 的):安全性是結構性的,來自
(a) provider 的單一配置語意 — secondary IP 恰好存在於一個 NIC 上 —
與 (b) 帶 reassignment 的 acquire(AWS
assign-private-ip --allow-reassignment將 IP 原子地移動,不等待停止的持有者釋放 — release-before-acquire 會在 主機故障時喪失活性)和 (c) NIC 範圍的 stale 操作(舊持有者的unassign僅針對自身 NIC, 無法剝離新持有者 NIC 上的 IP)的組合。 - On-prem 的 proxy-ARP 更弱。不得偽裝成與雲端等價: 沒有原子的 reassignment。此處的安全性依賴於 作為 capture 權限的 VRRP/keepalived master 狀態 — 非活躍節點 fail-closed (無 proxy-ARP、無 route lowering),僅 master 發出 proxy-ARP + GARP — 。 分割下的完全安全性在無 STONITH / 仲裁時不可實現, 超出範圍。
- 活性與安全性預算: lease TTL / 心跳間隔調節偵測延遲
(太短 → 震盪,太長 → 恢復慢)。對應 keepalived 的
advert_int和 現有的deprovisionHoldDuration遲滯。安全性不得依賴此旋鈕 — 提供安全性的僅有單調遞增captureEpoch。Kleppmann 教訓的具體化。
階段劃分
- Phase A(此 ADR 的最小範圍 — 確定性修復 #70): 引入
captureEpoch。 為 action 打戳。將標記改為 epoch 鍵控的層級投影。 epoch stale / holder 不匹配時在匯入處圍欄。移除 cancel 路徑和 wall-clock 生命週期 key。驗收條件:TestServeChainMobilityCancelsPendingDeprovisionWhenDesiredAgain以-count=100(及-race)確定性通過,斷言放寬(< 2) 替換為精確的確定性計數,re-emit 測試保持 green, 不透過放寬測試來通過。 - Phase B(後續): 用於突發 seize 的 execute-time 閘門(在 import-time 之外)。
- Phase C(後續 — 故障切換功能): 活性驅動的放置 —
不僅是
maintenance.drain旗標,還透過 lease TTL / 心跳驅動啟用。 突發主機故障觸發備援方的 seize(帶 reassignment 的 acquire),並對殭屍復活圍欄。 這是 D4(on-prem VRRP 故障切換)的雲版本, 將僅限排空的 migration(D5)轉變為 AWS / Azure / OCI 上的透明主機維護/ 實體主機故障切換。
結論
- Flaky 的 de-provision/re-capture 競爭在抽象層面消除,而非透過覆蓋: 一個確定性的 epoch 圍欄計算替換了分散的命令式取消。
- routerd 取得了原則性的 fencing token(
captureEpoch),同一閘門 後續也可用於突發故障切換的 seize — #70 修復和故障切換功能 共享一個機制。 - 設計明確說明雲端 capture 是強安全的(provider 的單一配置 + reassignment + NIC 範圍 + epoch),on-prem 的 proxy-ARP 是盡力而為的 (VRRP master 權限 + fail-closed + GARP),而非暗示兩者等價。
- 保持 simplicity-first 範圍:不引入共識協定(Paxos/Raft)。 每位址的單調遞增計數器 + 單一圍欄閘門就是協調面的全部。
-race驗收標準的修復還發現並修復了現有事件匯流排的資料競爭(publish 與 unsubscribe 的 channel close 競爭)。參見伴隨的fix(bus)commit。